
Gure etxe eta kotxeek euskaraz ere ulertu dezaten

Azken urtean adimen artifizialak (AA) izugarrizko garrantzia eta abiada hartu duela dirudi. Arlo honetan, hizkuntzaren prozesamentuak (ingelesez NLP, Natural Language Processing) eta honen aplikazio ezberdinek zeresan handia izan dute. ChatGPT edota Midjourney denon ahotan egon diren aplikazioak adibidetzat har ditzakegu, baina baditugu gertuago honekin lanean ari diren Elhuyar (aditu.eus eta Mycroft proiektuarekin) edota Vicomtech ere.

Aplikazio hauek baina, ez dira adimendun ezerezetik bihurtzen eta gurekin elkarrizketak eduki ahal izateko, hizkuntza ulertu eta irudi sorkuntzan jardun ahal izateko, aurretik ikasi egin behar izaten dute. Oso gainetik azaltzeko, sarean eskuratzen dituzten datu banku handiak erabili ohi dituzte programa hauek entrenatzeko eta AA hauen kalitatea ein handi batean datu hauen kalitate eta kantitatean datza: Zenbat eta kalitate hobeagoko testu gehiago prozesatu, ondorenean gurekin txat elkarrizketa txukun bat izateko aukera gehiago izango ditu. Eta irudiekin ere berdin, sarean aurkitutako zenbat eta irudi gehiago prozesatu, ondorenean irudi berri bat sortzeko jakintza gehiago izango ditu aplikazioak.
Puntu honetan, ziurrenik hainbati burura etorri zaizkio aplikazio hauek martxan jarri dituzten enpresen aurkako hainbat salaketa aurkeztu izan dituztela, beraien adimen artifizilak entrenatzeko erabilitako bai irudi eta baita testuek ere zuten Copyright lizentzia dela eta. Esan beharrik ez dago gainera CC lizentzia duten datu libreetan ere aitortzarik ere ez dutela egiten eta egile eskubideak arazo nabarmena ari direla izaten. Eta bestetik, entrenamenduetarako erabilitako material horrek AA horren funtzionamenduan duen eragin zuzena ere, dela joera matxistak garatu dituelako edota eskuin muturreko ideien bultzatzaile bihurtu delako: Zer ikusi, hura ikasi.
Horrela bada, honez gero konturatuko zineten zein garrantzitsua den AA hauek euskaraz ere entrenatzea. Zenbat eta euskarazko testu, audio gehiago ikasi aplikazio hauek, gero eta aukera gehiago izango baitugu beraiekin euskarazko interakzioak izateko. ChatGPTren kasuan adibidez, hasiera batean behintzat euskaraz elkarrizketa hala moduzkoak egiteko gai bazen, nahiz eta segituan aldatu zuten aukera eta gaztelaniaz erantzuten hasi zitzaigun.
Duela gutxi, ChatGPT sortu zuen OpenAI enpresak, Whisper deritzon adimen artifizialeko hizkuntza prozesamendurako aplikazioa denontzat libreki eskeintzen duela ikusi dugu. Oso labur esateko, Whisperri MP3 audio bat ematen badiozu, audio hori zein hizkuntzetan dagoen detektatu eta transkribatu egiten dizu. Hona hemen Artxipielagoaren trailerreko audioa pasata lortu genuen erantzuna:

Beraz euskaraz hala moduz bada ere badabil! Microsoft enpresaren azpian dagoen OpenAI enpresak euskara ere kontutan nolatan hartu du ba? Egiari zor, OpenAIri bost axola dio euskarak, baina Whisper entrenatzerako orduan domeinu publikoan edo lizentzia libreak dituzten datu bankuak erabili ditu, aurkitu dituen ahalik eta hizkuntza gehienetan entrenatzeko. Hauen artean, Common Voice, Mozillaren datu sorta, OpenAIk berak publiko egindako "paper" honetan ikus daitekeen bezalaxe. Jendeak boluntarioki grabatutako milaka esaldiren audioak hartu eta prozesatu dituzte eta datu sorta horretan euskarazko esaldi mordoxka bat ere badago.

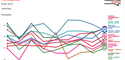
Ondorioz, Common Voice proiektu gero eta sendoagoa izan, hizkuntza prozesamendu hare eta hobeagoa duten AA aplikazioak sortuko liratekeela aurreikus daiteke. Eta euskaraz gero eta esaldi gehiago eta kalitate hobeagokoak eginez, euskaraz ere digitalizazio tresna gehiago eta hobeagoak izango genituzke. Hona beheko irudian Whisper garapenean, hizkuntza bakoitzak duen errore tasa. Zenbaki zenbat eta txikiagoa, orduan eta transkribapen hobea lortzen dela esan nahi du. Euskara ez da zerrendan agertu ere egiten.

Honelako beste hainbat proiektu ere badaude, tartean duela gutxi aipatu genuen Metaren (Facebook-en enpresaren) Massively Multilingual Speech (MMS) delakoa, non haien iritziz Whisperrek baino emaitza hobeak lortzen dituen eta 1.100 hizkuntza ulertzeko gai den. Kasu honetan Bibliako pasarte irakurriez osatutako datuekin eta baita VoxPopuli, Europarlamentuko hizlarien datuak erabiliz osatua ere. Gertuagoko enpresen (Elhuyar edo Vicomtech-en) tresnak ere badaude, baina ez ditugu zuzenean probatu. Pentsatu nahi dugu, euskararen transkribapenean askoz kalitate hobea lortuko dutela eta interesa duenarentzat aditu.eus-en doako probak egiteko aukera dago aurretik zure burua erregistratuta.
Tresna hauetako batzuk gainera, modu askotan erabili daitezke: bideoak/audioak transkribatzeko edota etxeko domotikan, ahotsezko aginduak testu bilakatu eta etxeko argiak piztu edo, garajeko atea irekitzeko. Azken hauxe egiten du Home Assistant, software librean oinarritutako domotikarako inguruneak, Whisperrek testu bilakatutako aginduak hartu, eta domotikan aplikatuz. Eta etxean grabatutako audio propio batekin egin genuen proba:
"Piztu sukaldeko argiak, mesedez. Piztu al ditzakezu sukaldeko argiak, mesedez. Zein tenperatura dago sukaldean? Esango al zenidake zein tenperatura dagoen sukaldean?" grabatu genuen eta agindu horiek transkribatu zituen Whisperrek. Argi dago beraz, oraingoz behintzat euskarak ez duela balio domotikarako eta Common Voice bezalako datu sortak elikatu eta sendotzen indarrak batu beharko genituzkeela, etorkizunean gure etxeek, kotxeek eta era guztietako gailuek euskara ulertu dezaten.
Kontu hauetan gehiago sakondu nahi duenak, Mastodon sare libre eta deszentralizatuan gai honen inguruko eztabaida hari bat piztu zen duela gutxi.





Erantzun
Sartu