
Mikel Artetxeren tesia: Itzulpen automatiko gainbegiratu gabea

Aste honetan Mikel Artetxe informikari euskaldunak bere tesia aurkeztu du, eta oporren bueltan Facebook-eko adimen artifizialeko unitatean hasiko da lanean, Londresen. Artetxe lanean ibili den IXA taldeak azaldu du haren tesiaren nondik norakoa, ekarpen handi bat itzulpengintza automatikoan, bereziki euskararentzat eta korpus elebidun antolatu oso handiak ez dituzten geurea bezalako hizkuntzentzat. Itzulpen automatiko gainbegiratu gabea izan da Artetxeren tesia.

Itzulpen automatikoan egindako aurrerapenak izugarriak izan dira azken bizpahiru urteetan. Bereziki, itzultzaile neuronalak edo, teknikoki, "Sekuentziatik sekuentziarako eredu neuronala" erabiltzen duen ereduak jauzia izan dira euskarazko itzulpengintza automatikoan, erderetarako norabidean zein euskararakoan. Sarean jarritako euskarazko adibideak dira horren adierazle: Batua.eus, Itzultzailea.eus, Jaurlaritzarena...
"Hala ere, gaur egun dauden sistemek datu asko behar dute (gainbegiratze sakona), corpus paralelo gisa normalean milioika perpaus behar izaten dituzte", dio IXAren testuak. "Baina harrigarria da, baldintza hori ez du behar gizakiak hizkuntza eskuratzeko. Eta gainera arazo praktiko garrantzitsu bat planteatzen du euskara bezalako baliabide gutxiko hizkuntzekin itzulpenak egiteko".
Egia da, hizkuntza batez "elebakarki" jabetu ohi da haurra; eta Mikel Artetxeren hurbilpena hortik doa, korpus elebidunen edo datu paraleloen mendekotasun hori ezabatzea. Prozedurak bi osagai ditu:
Bat. Korpus independenteak aztertzen dira, eta hitz-bektoreak lerrokatzen dira beren arteko egitura antzekotasunean oinarrituta. Adibidez, grafiko honek erakusten diguna:
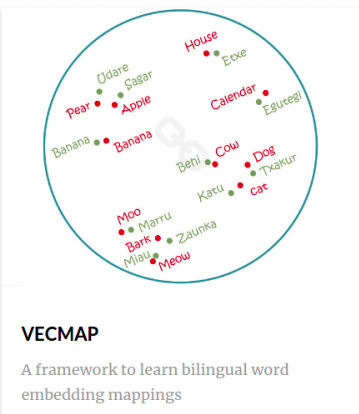
Euskara eta ingelesa independenteki aztertu ditu sistemak, baina hitzak, hizkuntza bakoitzean, bektore espazio berdintsuan kokatu dira. Animalia izenak elkarrengandik gertu daude, adibidez, eta haiek osatzen duten multzotik gertu beste multzo bat dago, animalien hotsekin (marrua, zaunka). Irudiak zirkulu batean erakusten dituen multzokatzea irudikatze sinple bat dira: izatez, bektore lerrokatzea ez da 2 dimentsioko plano bakarrean gertatzen, baizik eta 300 dimentsio kontuan hartzen dituen espazio batean. Konputazio lan pixkat badago hor, beraz.
Bi. Aurreko teknikekin egindako hitzen lerrokatze hori, darabil Artetxeren metodoak itzulpen-sistema neuronal bat edo itzulpen-sistema estatistiko bat hasieratzeko, "azken urratsean back-translationaren bidez hobetzen joango dena". Uste dugu, feedback automatizatuen bidez ikastekon eta hobetzeko prozesu bat deskribatzen dela hitz horiekin.
IXAkoen azalpena, hemen.
Mikel Artetxe jarraitzeko: @artetxem Twitterren, webgunea.






Erantzun
Sartu